Web Apps Opera Bork Edition
It’s been 18 years since Opera published their classic bork edition, to protest that MSN would have loaded properly in the browser if only it were served the same code as Internet Explorer.
“Hergee berger snooger bork,” says Mary Lambert, product line manager desktop, Opera Software. “This is a joke. However, we are trying to make an important point. The MSN site is sending Opera users what appear to be intentionally distorted pages. The Bork edition illustrates how browsers could also distort content, as the Bork edition does. The real point here is that the success of the Web depends on software and Web site developers behaving well and rising above corporate rivalry.”
Since I’m a Vivaldi user, today’s the first time I noticed that Chrome on Android artificially restricts installing webpages as apps on the homescreen. Only webpages that specify a manifest.json can receive such a hallowed treatment, instead of every single webpage ever made. For the rest of the internet, there’s only a shortcut. While the situation is not quite comparable, I found the design principle sufficiently distasteful to revive Opera’s classic bork script, in this case specifically targeting the Chrome browser.
You can put it on your website or in your TamperMonkey to remind you when you accidentally open Chrome. The classic result looks like this:
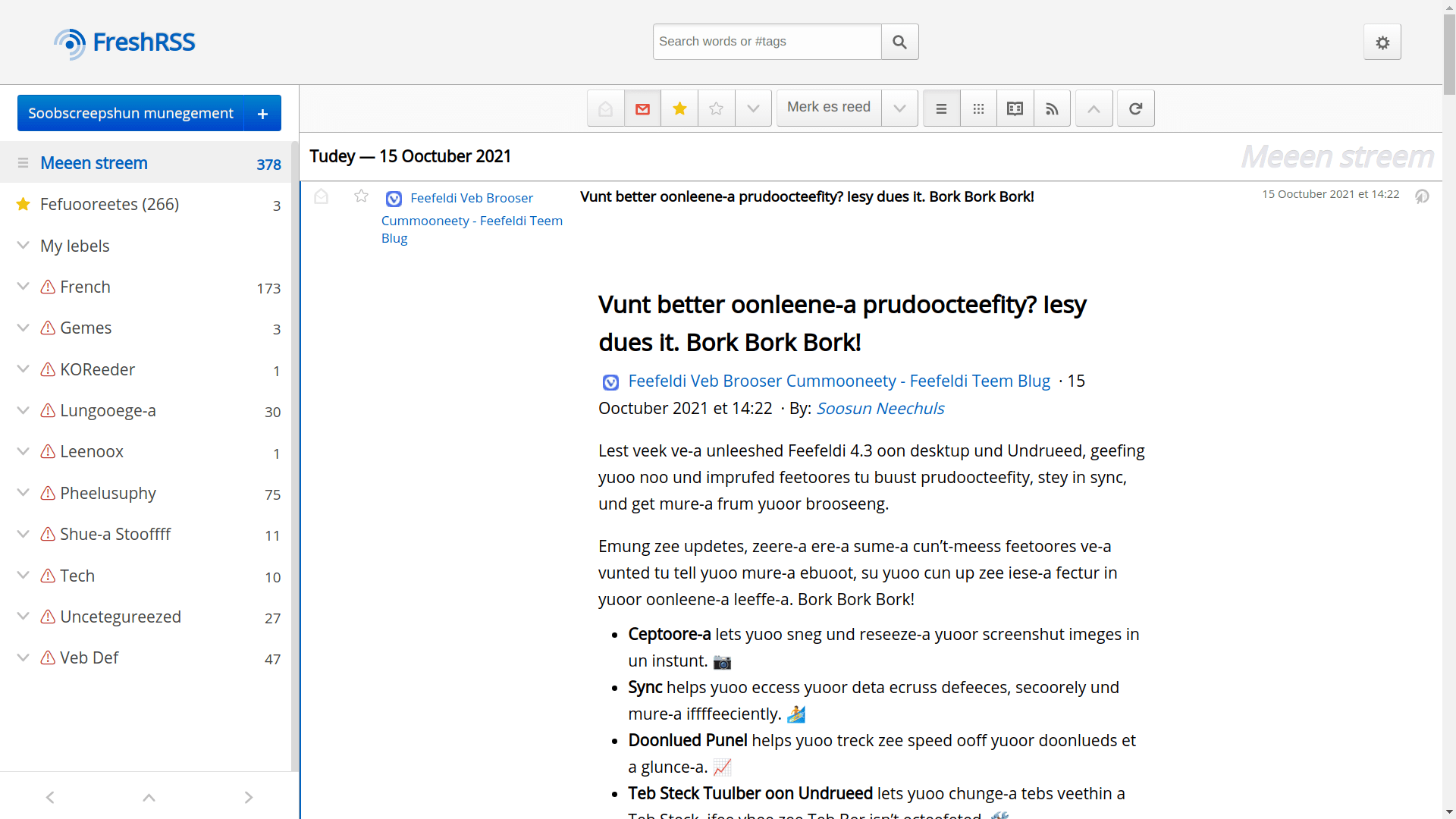
// http://web.archive.org/web/20050301075735/http://www.opera.com/js/bork/enchefizer.js
/* -*- mode: C++; mode: font-lock; tab-width: 4 -*-
* 2003-02-10
*
* The Enchefizer code is based on a script fetched from
* http://tbrowne.best.vwh.net/chef/
* written by Andriy Rozeluk , which is
* based on a Java version written by Josh Vura-Weis
* , which is based on a UNIX version
* from 1993 written by John Hagerman and
* Jeff Allen
*
* Subsequently hacked by Opera Software to work inside a page by
* traversing the DOM tree, and to improve performance.
*
* Typical usage is to add the following text to the bottom of a page:
*
*/
const classicOperaBork = () => {
/* USER CONFIGURATION BEGINS */
var victim=false; // false (apply to any page) or regex to match page URL
//var victim=/^http:\/\/(?:(?:www|msdn).microsoft.com|www.msn.com)/;
var delay=50; // ms between replacements, set to 0 to disable waiting
var units=30; // number of text nodes to translate each time
var highlight=true; // highlight the text we're working on
/* USER CONFIGURATION ENDS */
var textnodes=[]; // text nodes in the doc
var nextnode=0; // next node to process
function nextWordPos(line)
{
var p = line.search(/[ \n\t\\,<.>/?;:\'\"\[{\]}|=+\-_!@#$%^&*()~`]/);
return p == -1 ? line.length+1 : p;
}
function encheferizeLine(line)
{
var buff="", word="", t="", out="", wp;
while(line.length > 0)
{
wp = nextWordPos(line);
word = line.substring(0,wp);
t = line.charAt(wp);
line = line.substring(wp+1,line.length);
out = out + encheferizeWord(word) + t;
}
if(t == ".")
{
out = out + "\nBork Bork Bork!";
}
return out;
}
function encheferizeWord(word)
{
if(word.toLowerCase() == "bork") return word;
var letter, count, len, buff, i_seen, isLast;
count=0;
len=word.length;
buff=""
i_seen=false;
while(count0){
}
} else if(letter=='t'){
if(count==len-2 && word.charAt(count+1)=='h'){
buff = buff + "t";
count+=2;
continue;
} else if(count<=len-3 && word.charAt(count+1)=='h'
&& word.charAt(count+2)=='e'){
buff = buff + "zee";
count+=3;
continue;
}
} else if(letter=='T' && count<=len-3 && word.charAt(count+1)=='h'
&& word.charAt(count+2)=='e'){
buff = buff + "Zee";
count+=3;
continue;
} else if(letter=='v'){
buff = buff + "f";
count++;
continue;
} else if(letter=='V'){
buff = buff + "F";
count++;
continue;
} else if(letter=='w'){
buff = buff + "v";
count++;
continue;
} else if(letter=='W'){
buff = buff + "V";
count++;
continue;
}
//End of rules. Whatever is left stays itself
buff = buff + letter;
count++;
}
return(buff);
}
function bork()
{
var limit = delay == 0 ? Number.MAX_VALUE : units;
var start=nextnode;
var oldc = new Array();
var n, i, candidate;
if (highlight)
{
for ( n=start, i=0 ; i < limit && n < textnodes.length ; n++, i++ )
{
candidate = textnodes[n];
oldc[i] = candidate.parentNode.style.backgroundColor;
}
for ( n=start, i=0 ; i < limit && n < textnodes.length ; n++, i++ )
{
candidate = textnodes[n];
candidate.parentNode.style.backgroundColor = 'red';
}
}
for ( i=0 ; i < limit && nextnode < textnodes.length ; nextnode++, i++ )
{
candidate = textnodes[nextnode];
candidate.replaceData(0,candidate.length,encheferizeLine(candidate.data));
}
if (highlight)
{
for ( n=start, i=0 ; i < limit && n < textnodes.length ; n++, i++ )
{
candidate = textnodes[n];
candidate.parentNode.style.backgroundColor = oldc[i];
}
}
bork_more();
}
function bork_more()
{
if (nextnode < textnodes.length)
{
setTimeout( bork, delay );
}
}
/* In large docs traversal is a bottleneck at startup; we could
CPS it or otherwise reify the traversal state to interleave
traversal with the translation.
*/
function find_textnodes(elm, acc)
{
if (elm.nodeType == 3)
{
if (!elm.data.match(/^[\s\n\r]*$/))
{
acc.push(elm);
}
}
else
{
var c = elm.childNodes;
for ( var i=0 ; i < c.length ; i++ )
{
find_textnodes(c.item(i),acc);
}
}
return acc;
}
/* run page's onload handler, then do our thing */
var res = false;
if (typeof old_onload == "function")
{
res = old_onload();
}
if (/*window == top &&*/ (!victim || window.location.href.match(victim)) )
{
textnodes = find_textnodes(document.body, new Array());
nextnode=0;
bork_more();
}
return res;
}
if (window.navigator.userAgentData.brands.filter(e => e.brand === 'Google Chrome').length > 0) {
document.addEventListener('DOMContentLoaded', classicOperaBork);
} Permalink CommentsTags: javascript