Disable Firefox Fullscreen Animation
Go to about:config, as ever. Then disable browser.fullscreen.animate.
Go to about:config, as ever. Then disable browser.fullscreen.animate.
dns-prefetch from WordPress 4.9Most people seem to have switched to statically generated blogs like Hugo by now, but I’ve been using WordPress for some 13 years and combined with WP-Super-Cache it’s been static for pretty much that entire time. There’s little point to putting in extra time and effort just for some extra nerd cred.
On the downside, every new 4.0+ release seems to add more cruft to the header. My functions.php consists of an ever-growing list of remove_action incantations. Here’s the latest addition, necessitated by WordPress 4.9.
// remove WP 4.9+ dns-prefetch nonsense
remove_action( 'wp_head', 'wp_resource_hints', 2 );For those interested, here’s my full messy collection, including a few hints I commented out.
add_post_type_support( 'page', 'excerpt' );// See http://wordpress.mfields.org/2010/excerpts-for-pages-in-wordpress-3-0/
remove_action('wp_head', 'rsd_link');// Windows Live Writer? Ew!
remove_action('wp_head', 'wlwmanifest_link');// Windows Live Writer? Ew!
remove_action('wp_head', 'wp_generator');// No need to know my WP version quite that easily
// remove WP 4.2+ emoji nonsense
remove_action( 'wp_head', 'print_emoji_detection_script', 7 );
remove_action( 'admin_print_scripts', 'print_emoji_detection_script' );
remove_action( 'wp_print_styles', 'print_emoji_styles' );
remove_action( 'admin_print_styles', 'print_emoji_styles' );
// remove WP 4.9+ dns-prefetch nonsense
remove_action( 'wp_head', 'wp_resource_hints', 2 );
// disable embeds nonsense; not even sure what it does
// Remove the REST API endpoint.
remove_action('rest_api_init', 'wp_oembed_register_route');
// Turn off oEmbed auto discovery.
// Don't filter oEmbed results.
remove_filter('oembed_dataparse', 'wp_filter_oembed_result', 10);
// Remove oEmbed discovery links.
remove_action('wp_head', 'wp_oembed_add_discovery_links');
// Remove oEmbed-specific JavaScript from the front-end and back-end.
remove_action('wp_head', 'wp_oembed_add_host_js');
// Jetpack
//remove_action('wp_head', 'shortlink_wp_head'); // Don't need wp.me shortlinks
// No jQuery! (als Jetpack
//if( !is_admin()){
//wp_deregister_script('jquery');
//wp_register_script('jquery', ("http://ajax.googleapis.com/ajax/libs/jquery/1.3.2/jquery.min.js"), false, '1.3.2');
//wp_enqueue_script('jquery');
//}
// remove OneAll Social script from regular page
remove_action ('wp_head', 'oa_social_login_add_javascripts');When I logged in, WordPress tried to inform me that the particular browser I was using was out of date.

So, is it?
Well, we can take a look at the Firefox ESR download page to find out.
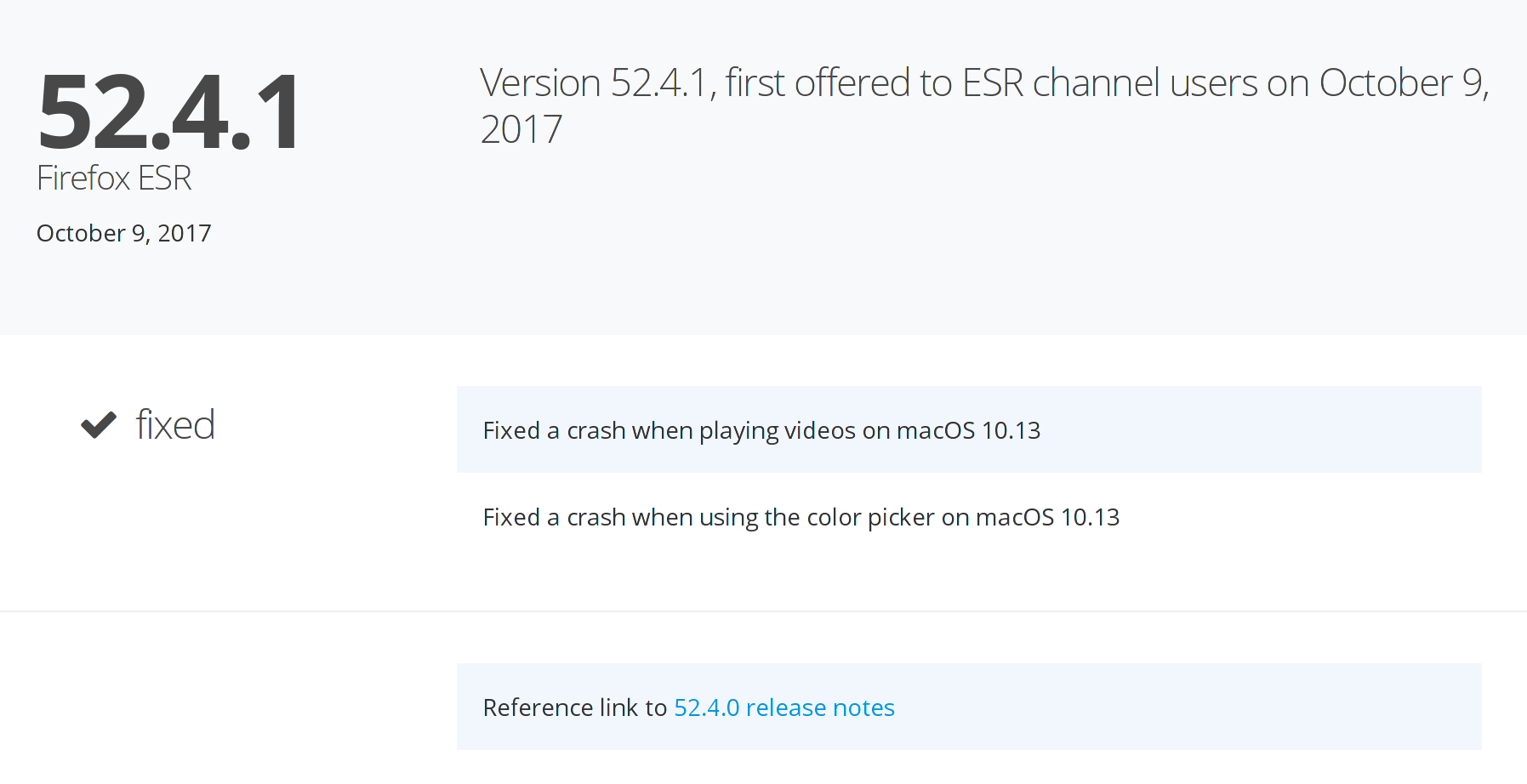
Nope. Still Firefox 52, which will remain supported until Firefox 60.
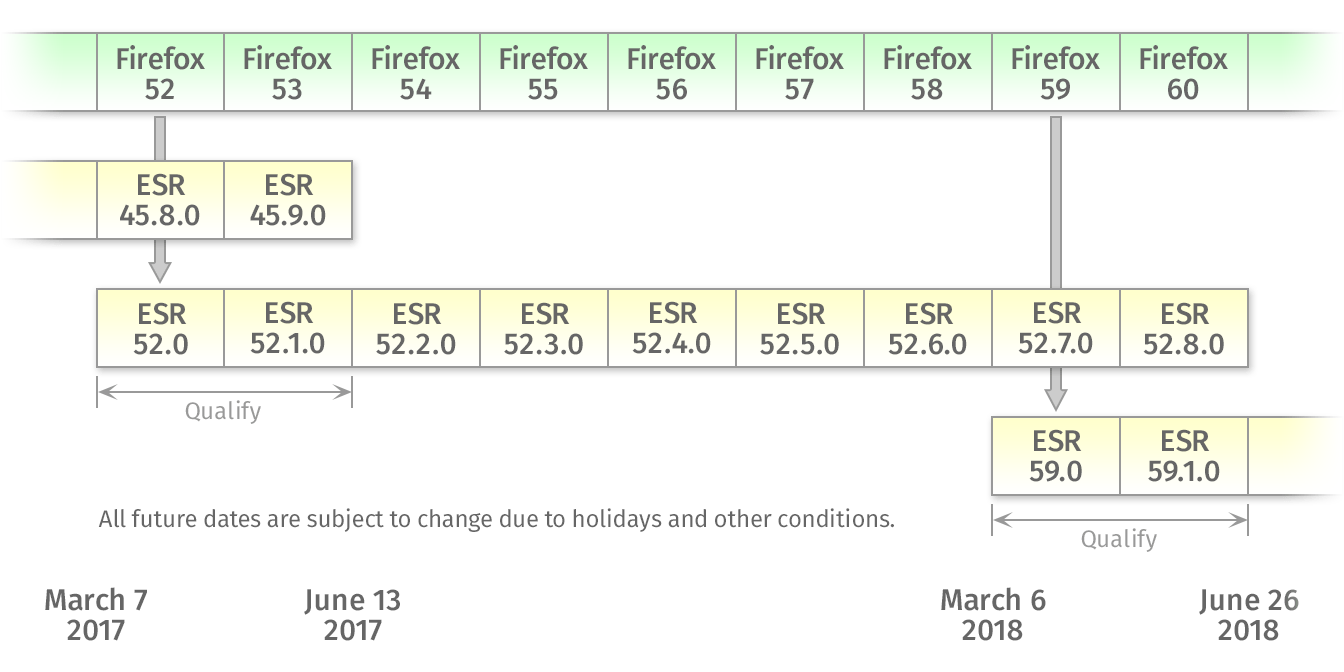
Always fun, these automated checks. 🙂
On the forum I administer, I am forced to run a tight attachment policy. Disk space doesn’t grow on trees. Occasionally this leads to questions about the small attachment size limit of 50 KiB. This guide is intended to clarify that this is not nearly as tiny as you might think. Note that although I’ll mention commands without much explanation for the sake of brevity, you’re always recommended to further explore the possibilities offered by those commands with the --help flag as well as by running man the-command-here.
First you need to ask yourself what kind of file type is appropriate, if you have the choice. On screenshots, the main purpose of attachments on my forum, you’ll often encounter large areas of uniform background colors. PNG is therefore almost invariably the right choice. Crop out everything but what’s relevant. JPEG is appropriate for more dynamic pictures such as photographs. If you want to do a lot with photographs, you might want to consider an external hosting service. My wife likes SmugMug. Still, for thumbnails you might be able to do a fair bit more within a few hundred KiB than you might think. Finally, the vector graphics in SVG result in pictures that always look sharp. You’ll typically have drawn these in a program like Inkscape or Adobe Illustrator.
Often you’ll want to crop your file. Do not edit your JPEG followed by resaving it because this will result in reduced quality! You can crop losslessly with cropgui. On Windows you can use IrfanView.
If you don’t want to crop, and also potentially for some post-cropgui optimization, use jpegtran -copy none -progressive -optimize file.jpg > file-opt.jpg. Note that this will get rid of all metadata, which may be undesirable. If so, use jpegtran -copy all -progressive -optimize file.jpg > file-opt.jpg.
Of course if you want to scale down your JPEG there’s no point in mucking about with lossless cropping first. After scaling down, check how low your quality can go (also see a little helper script I wrote). In any case, you should avoid introducing any unnecessary compression steps with associated quality loss. Here are some results:


-copy all -progressive -optimize 11-crop-opt.jpg at 1.04 MB. -copy none would’ve saved an extra whopping 40-some KiB, which on this kind of filesize has little benefit, and besides, I quite like the metadata. For thumbnail-sized files the balance is likely to be different. For example, the 52.2 KiB SmugMug auto-generated thumbnail below can be insignificantly reduced to 51.1 KiB with --copy all, but to 48.2 KiB with --copy none. I think an 8% reduction is not too shabby, plus it brings the file size down to under the arbitrary 50 KiB limit on my forum.
As I wrote in the introduction, for screenshots PNG is typically the right choice. If you want to use lossless PNG, use optipng -o7. In my experience it’s ever so slightly smaller than other solutions like pngcrush. But as long as you use a PNG optimizer it shouldn’t much matter which one you fancy. Also see this comparison.
If you don’t care about potentially losing some color accuracy, use pngquant instead. To top it off, if you really want to squeeze out your PNG, you can pass quality settings with --quality min-max, meaning you can pass --quality 30-50 or just --quality 10. Here are some quick results for the screenshot in the SVG section below, but be sure to check out the pngquant website for some impressive examples.
$ du -h --apparent-size inkscape-plain-svg.png
27K inkscape-plain-svg.png
$ du -h --apparent-size inkscape-plain-svg-fs8\ default.png
7.6K inkscape-plain-svg-fs8 default.png
$ du -h --apparent-size inkscape-plain-svg-fs8\ quality\ 10.png
4.3K inkscape-plain-svg-fs8 quality 10.png
In this case there is no visual distinction between the original PNG and the default pngquant settings. The quality 10 result is almost imperceptibly worse unless you look closely, so I didn’t bother to include a sample.
For using SVG on the web, I imagine I don’t have to tell you that in Inkscape, you should save your file as Plain SVG.

Save as Plain SVG in Inkscape.
What you may not know is that just like there are lossy PNGs, you can also create what amounts to lossy SVGs. There are some command-line tools to optimize SVGs, including (partially thanks to this SO answer):
scour < in.svg > out.svg or scour -i in.svg -o out.svg. But I recommend you go further.My personal preference for squeezing out every last byte goes toward the web-based version of the SVG-editor by Peter Collingridge. By running it in a browser with inferior SVG support such as Firefox, you’ll be sure that your optimized SVG still works properly afterward. The command line tools can only safely be used for basic optimizations, whereas the effects of going lossy (such as lowering precision) can only be fully appreciated graphically.
Scanned documents are a different item altogether. The best format for private use is DjVu, but for public sharing PDF is probably preferable. To achieve the best results, you should scan your documents in TIFF or PNG, followed by processing with unpaper or ScanTailor. If you’ve already got a PDF you’d like to improve, you can use pdfsandwich or my own readablepdf.
I’m not aware of any lossless optimization for video compression such as offered by jpegtran, but you can often losslessly cut video. In the general purpose editor Avidemux, simply make sure both video and audio are set to copy. There is also a dedicated cross-platform app for lossless trimming of videos called, unsurprisingly, LosslessCut. If you do want to introduce loss for a smaller file size you can use the very same Avidemux with a different setting, ffmpeg, mpv, VLC, and so forth. You can get reasonable quality that’ll play many places with something like:
ffmpeg -i input-file.ext -c:v libx264 -crf 19 -preset slow -c:a libfaac -b:a 192k -ac 2 output-file.mp4For the open WebM format, you can use something along these lines:
ffmpeg -i input.mp4 -c:v libvpx -b:v 1M -c:a libvorbis output.webmMore examples on the ffmpeg wiki. Note that in many cases you should just copy the audio using -acodec copy, but of course that’s not always an option. Extra compression artifacts in audio detract significantly more from the experience than low-quality video.
Permalink Comments (2)Tags: svg
Just so long as you don’t depend on it. In this case we’ve got Gmail’s automated translation feature, which I’ve probably only used once or twice in the past decade in order to see how it worked. Today it had the nice idea to suggest interference in English.
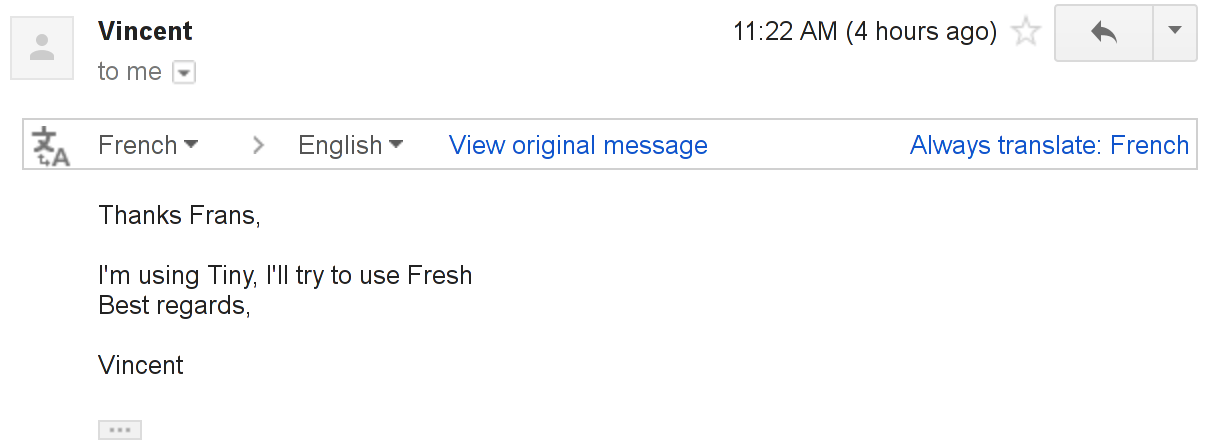
There is in fact French text hiding in the conversation history. Funny thing though — there’s no suggestion to translate on any of the preceding or following messages that are actually in French. So it goes.
Permalink Comments (1)Tags: French
QuiteRSS is a terrific piece of software. It only has one flaw, which is that it only runs on my desktop. Unfortunately this has led to me increasingly getting behind on the things I like to read. Sometimes this is fine, like when I can read a book instead, but other times it’s mildly frustrating.
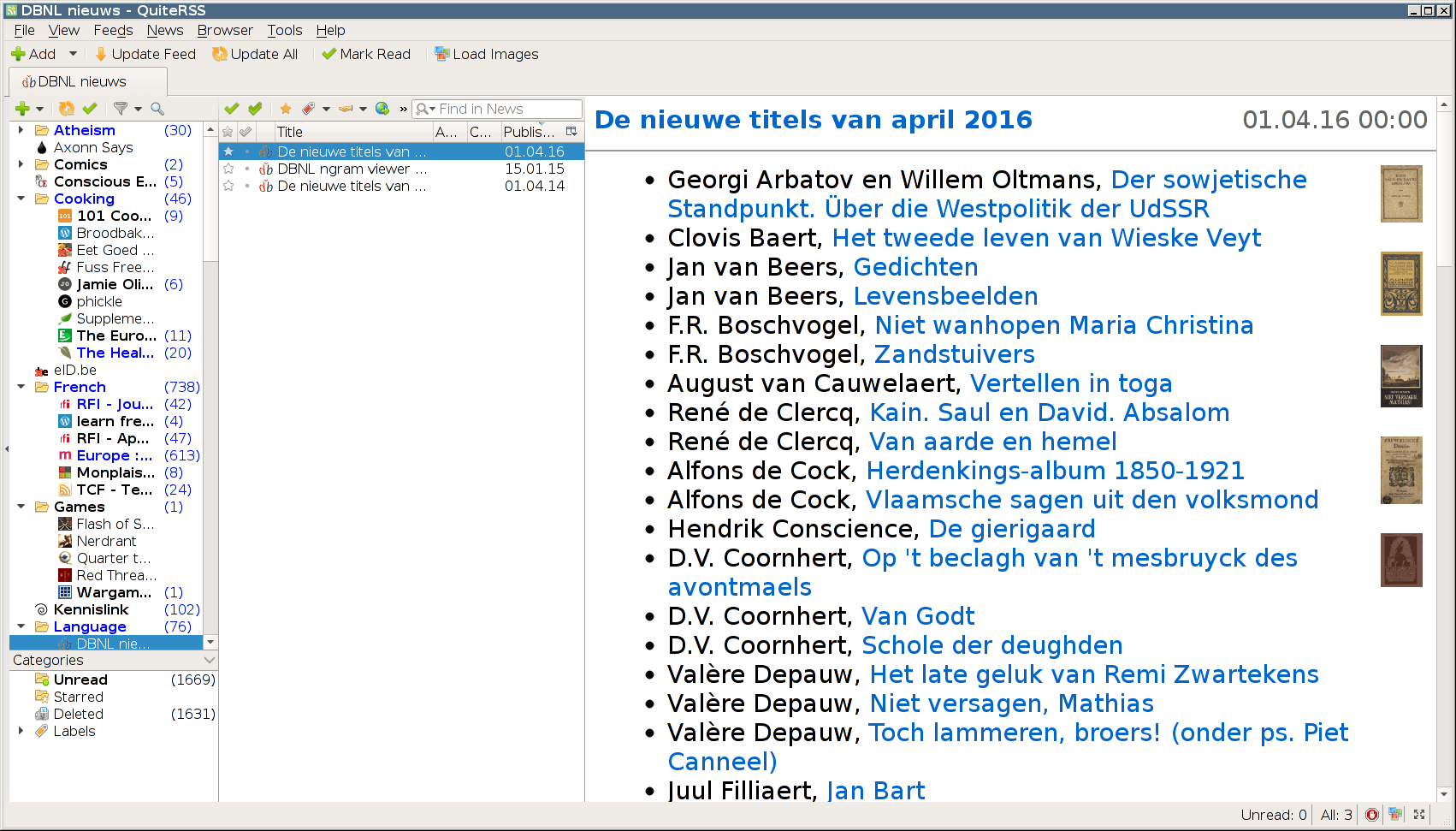
It would seem that none of the online feeds readers, whether self-hosted or SaaS, support the paradigm I’m used to. They’re all following the “golden standard” of nightmarish, thankfully-it’s-gone Google Reader. Basically I use feeds like emails. Most I delete after reading. Those I want to keep for reference I keep around, marked read.
But not so with these feedreaders. Feeds you want to keep for later reading should preferably be favorited, bookmarked, or maybe saved to a system like Wallabag. This has advantages too, of course. By centralizing your to-read list in one location, like Wallabag or Pocket, you don’t have the problem of remembering what’s where, or that you have loads of unread open tabs in various browsers.
Long story short, after sampling a whole bunch of feedreaders I opted for FreshRSS. It suffers from the omnipresent “no pages” disease. Got a feed with a thousand items? (Yes, they exist.) You can go to the start or the beginning by sorting in ascending or descending order, but reading things somewhere down the middle? Forget it.
These minor inconveniences are worth it, however. This way I can easily read my feeds from any computer anywhere in the world. The feeds are always updated, provided you set up a cron job. I don’t have to start up my computer or risk missing anything if I’m on vacation for a few days. I can quickly check them on my cellphone during an otherwise wasted moment. Overall I’m happy. Goodbye, QuiteRSS. You were a good friend after Opera died, but it’s time to move on.
PS Here are some feed-related links that should go along nicely with any feed reader.
I was suddenly having trouble connecting to GitHub, after pulling in an OpenSSH update to version 7. Chances are that means the problem is security-related, meaning it’s worthwhile to take the time to investigate the cause.
$ git pull
Permission denied (publickey).
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.A little debugging showed the following:
$ ssh -vT git@github.com
OpenSSH_7.1p2 Debian-2, OpenSSL 1.0.2f 28 Jan 2016
debug1: Reading configuration data /etc/ssh/ssh_config
debug1: /etc/ssh/ssh_config line 19: Applying options for *
debug1: Connecting to github.com [192.30.252.130] port 22.
debug1: Connection established.
[…]
debug1: Skipping ssh-dss key /home/frans/.ssh/id_dsa for not in PubkeyAcceptedKeyTypes
[…]
debug1: No more authentication methods to try.
Permission denied (publickey).Of course I could quickly fix the problem by adding PubkeyAcceptedKeyTypes ssh-dss to ~/.ssh/config, but checking OpenSSH.com tells me that “OpenSSH 7.0 and greater similarly disables the ssh-dss (DSA) public key algorithm. It too is weak and we recommend against its use.” So, although I could obviously re-enable it easily, I guess I’ll have to generate a new key. I hope GitHub’s guide is accurate for generating something sufficiently secure, because I’m kind of ticked off that something I generated in 2013 is already considered “legacy.” I hope I’m to blame and not an earlier version of GitHub’s guide.
Incidentally, to change the passphrase one would use the -p option, e.g.:
ssh-keygen -f id_rsa -pPrince makes it really easy to do all of the usual things with page numbers, like a different numbering scheme in the front matter and whatnot. Unfortunately you can’t counter-increment on @page, but thanks to Prince.addScriptFunc() you’ve got something better.
h2 {counter-reset: page 50}
@page {
@bottom-left {
content: prince-script(fixpagenum, counter(page));
margin-left: 2cm;
}
}In this CSS, instead of passing regular generated content, we’re passing a prince-script. That script has to be defined somewhere, like this.
Prince.addScriptFunc("fixpagenum", function(pagenum) {
pagenum = Number(pagenum);
pagenum = pagenum + pagenum - 50;
return pagenum;
});
The rationale in this case was to generate two separate documents, starting at page 50, one only left pages and the other only right pages. (Of course, the other one started at page 51.) I combined them with pdftk’s shuffle command.
pdftk left.pdf right.pdf shuffle output combined.pdfI don’t think there’s a way to do something like this purely in Prince using CSS, but I’d love to be proved wrong.
I was happily using Belgacom FON Autologin instead of the behemoth of an official Belgacom app, but ever since Belgacom updated their portal code I’ve barely been able to connect at all. That’s Belgacom’s fault, not the app’s. I haven’t been able to connect through the web interface or the official app either, because it just times out or gives mysterious errors. Unfortunately Belgacom FON Autologin pretends to be a browser by sending information over the HTTP protocol, so it equally fails to connect.
Luckily I just came across FON AccessFon, an app that utilizes the WISPr protocol. In a magnificent 33 kB it manages to connect to Belgacom FON quickly and efficiently, and for every FON router rather than just Belgacom’s to boot.
With a bit of trial and error it worked out like this. Alternatively you could use /opt.
Create a file called something like firefox.desktop in /home/username/.local/share/applications/
In that file, put:
[Desktop Entry]
Type=Application
Name=Firefox
GenericName=Web Browser
X-GNOME-FullName=Firefox Web Browser
Exec=/home/username/programs/firefox/firefox %u
Terminal=false
X-MultipleArgs=false
Type=Application
Icon=/home/username/programs/firefox/browser/icons/mozicon128.png
Categories=Network;Webbrowser;
MimeType=text/html;text/xml;application/xhtml+xml;application/xml;application/vnd.mozilla.xul+xml;application/rss+xml;application/rdf+xml;image/gif;image/jpeg;image/png;x-scheme-handler/http;x-scheme-handler/https;
StartupWMClass=Firefox-bin
StartupNotify=trueTo make it the default system-wide, manually add it to Xfce’s Preferred applications or your window manager’s equivalent. Also add it to Debian’s alternative system.
$ sudo update-alternatives --install /usr/bin/x-www-browser x-www-browser /home/username/programs/firefox/firefox 20
[sudo] password for username:
$ sudo update-alternatives --config x-www-browser
There are 2 choices for the alternative x-www-browser (providing /usr/bin/x-www-browser).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/bin/iceweasel 70 auto mode
1 /home/monkey/programs/firefox/firefox 20 manual mode
2 /usr/bin/iceweasel 70 manual mode
Press enter to keep the current choice[*], or type selection number: 1
update-alternatives: using /home/monkey/programs/firefox/firefox to provide /usr/bin/x-www-browser (x-www-browser) in manual modeIt’s not very pretty, but it does the trick.